Abstract
The Indo-European Cognate Relationships (IE-CoR) dataset is an open-access relational dataset showing how related, inherited words (‘cognates’) pattern across 160 languages of the Indo-European family. IE-CoR is intended as a benchmark dataset for computational research into the evolution of the Indo-European languages. It is structured around 170 reference meanings in core lexicon, and contains 25731 lexeme entries, analysed into 4981 cognate sets. Novel, dedicated structures are used to code all known cases of horizontal transfer. All 13 main documented clades of Indo-European, and their main subclades, are well represented. Time calibration data for each language are also included, as are relevant geographical and social metadata. Data collection was performed by an expert consortium of 89 linguists drawing on 355 cited sources. The dataset is extendable to further languages and meanings and follows the Cross-Linguistic Data Format (CLDF) protocols for linguistic data. It is designed to be interoperable with other cross-linguistic datasets and catalogues, and provides a reference framework for similar initiatives for other language families.
Background: the Indo-European languages and phylogenetic research
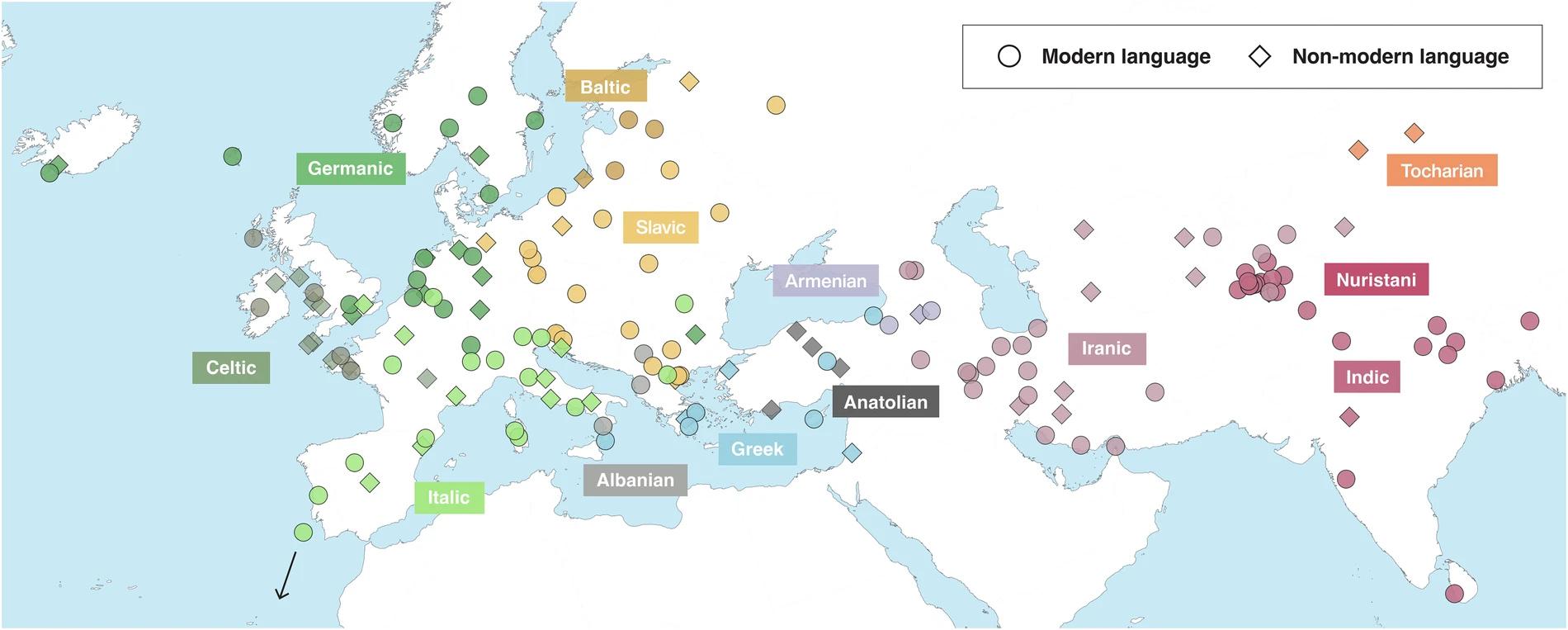
Almost half of the world’s population speaks a language of the Indo-European lineage. This huge family of over 400 languages has a long research tradition stretching back well over two hundred years, but much remains to be understood about its origins, dispersal, and internal structure. In particular, major phylogenetic analyses in recent years, as surveyed in, have supported conflicting hypotheses for the time depth and geographical origin of Indo-European. Recent analyses have mostly used state-of-the-art Bayesian phylogenetic analysis tools, applied to datasets of cognates (related words) across the Indo-European languages, i.e. forerunners of the new IE-CoR dataset presented here. Those past datasets have been criticised, however, for their limited and uneven coverage of the Indo-European family through time and space, and across its internal diversity, as well as for poor data coding — data problems directly implicated in the inconsistent phylogenetic results obtained.
The new Indo-European Cognate Relationships (IE-CoR) dataset is designed to overcome the limitations of past datasets. It encodes cognate relationships in 170 meanings of core vocabulary (i.e. basic terms like hand, drink, black, three) across 160 Indo-European languages. (For explanations of linguistic terminology used in this text, such as ‘cognate’, see the Definitions box.) IE-CoR aims to provide a benchmark dataset for quantitative and phylogenetic research on the Indo-European (IE) language family.
Anderson, C., Scarborough, M., Jocz, L. et al. The Indo-European Cognate Relationships dataset. Sci Data 12, 1541 (2025). https://doi.org/10.1038/s41597-025-05445-3